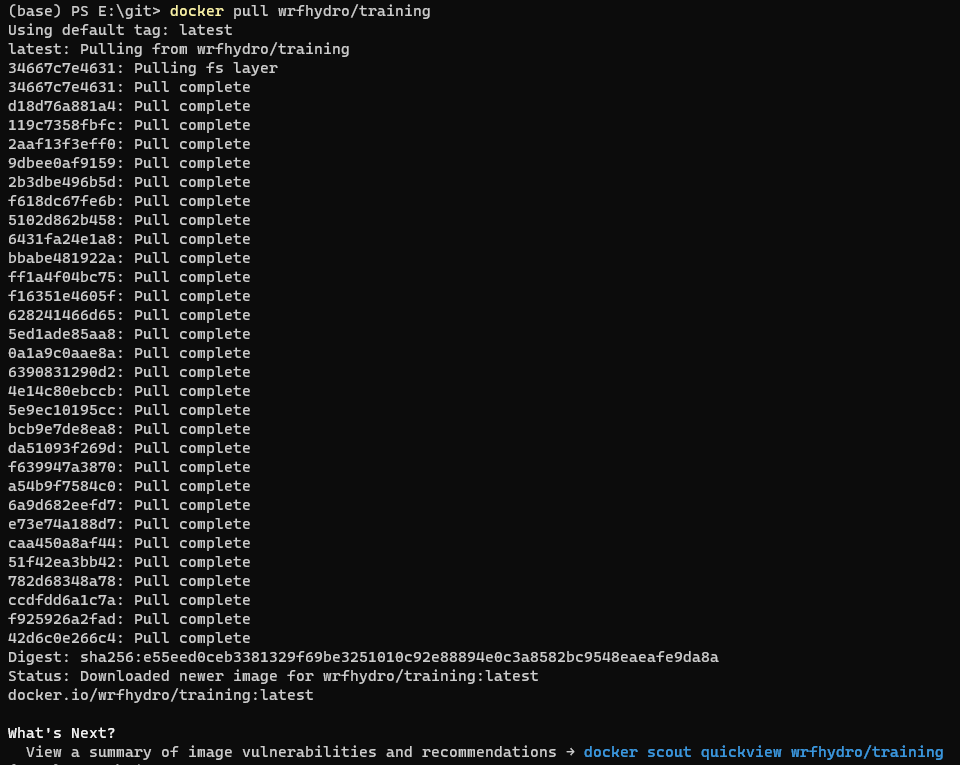
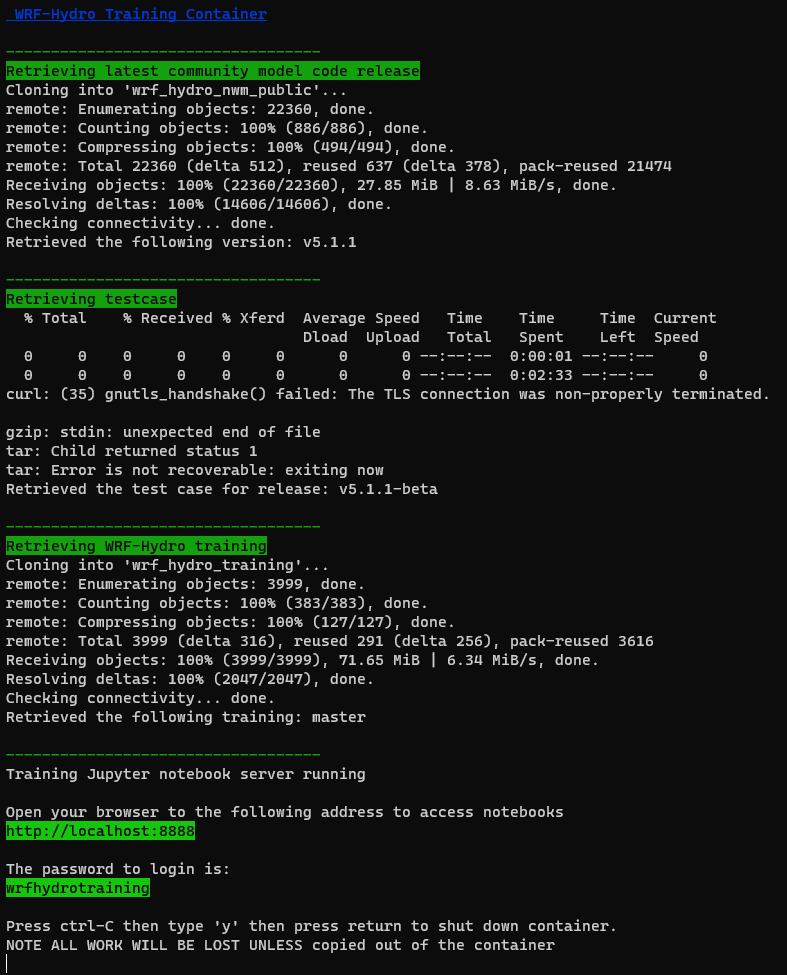
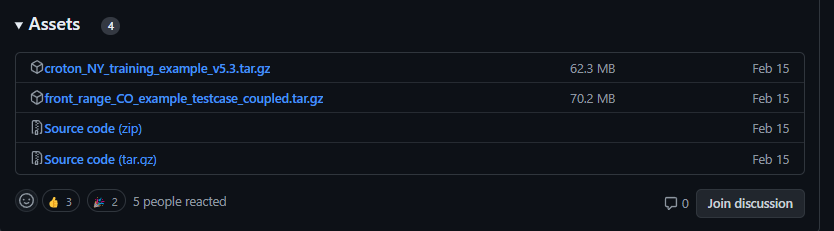
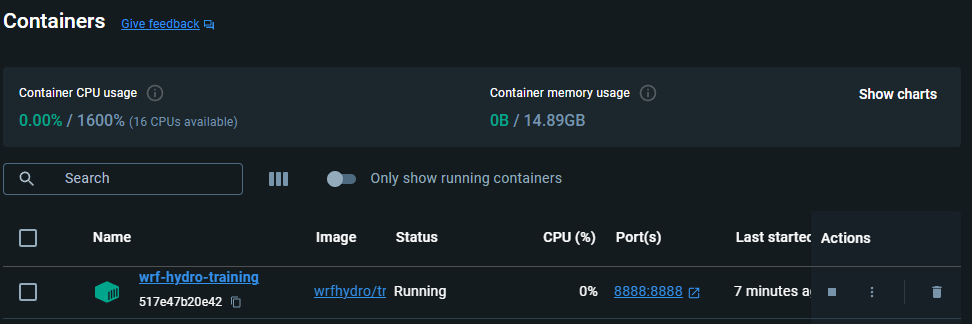
//////////////////////////////////////////////////////////////////// // Modifiable Area ^ // Modifiable Area | /////////////////////////////////////////////////////////////////////
Table 1. Descriptions of the contents of each source code sub-directory.
File/directory name
Description
arc/
Contains macro files, which specify the compile configurations, compiler options, links to netCDF libraries, etc.
cmake_modules/
Utilities for the experimental CMake build
CPL/Noah_cpl/
WRF-Hydro coupling interface for coupling WRF-Hydro components with the standalone (offline) Noah land surface model data assimilation and forecasting system
CPL/NoahMP_cpl/
WRF-Hydro coupling interface for coupling WRF-Hydro components with the standalone (offline) Noah-MP land surface model data assimilation and forecasting system
CPL/WRF_cpl/
WRF-Hydro coupling interface for coupling WRF-Hydro components with the WRF system
CPL/CLM_cpl/, CPL/LIS_cpl/, CPL/NUOPC_cpl/
Work in progress for ongoing coupling work
Data_Rec/
Contains some data declaration modules
Debug_Utilities/
Debugging utilities
deprecated/
Files not currently in use
Doc/
Pointer to location of full documentation
HYDRO_drv/
High-level WRF-Hydro component driver
IO/
I/O interfaces
Land_models/Noah/
Noah land surface model driver for standalone applications
Land_models/NoahMP/
Noah-MP land surface model driver for standalone applications
MPP/
MPI parallelization routines and functions
nudging/
Nudging data assimilation routines and functions
OrchestratorLayer/
Modules for namelist reads and eventually high level model orchestration
Rapid_routing/
Contains code for the RAPID routing model coupling (unsupported and out of date)
Routing/
Modules and drivers related to specific routing processes in WRF-Hydro
template/
Example namelist files for Noah, Noah-MP, and the WRF-Hydro modules (HYDRO) and example parameter tables for HYDRO. Note: Parameter tables for Noah and Noah-MP are stored within the Land_models directory. A sample bash script (setEnvar.sh) that could be passed to the compile script listing compile time options for WRF-Hydro is also located here.
utils/
Generic utilities used throughout the code
compile_offline_Noah.sh
Script for compiling WRF-Hydro standalone version with the Noah land surface model
compile_offline_NoahMP.sh
Script for compiling WRF-Hydro standalone version with the Noah-MP land surface model
configure
Script to configure the WRF-Hydro compilation
Makefile
Top-level makefile for building and cleaning WRF-Hydro code
README.build.txt
WRF-Hydro build instructions for the standalone model
wrf_hydro_config
Configure script for coupled WRF-Hydro configuration
*.json
JSON files used for testing
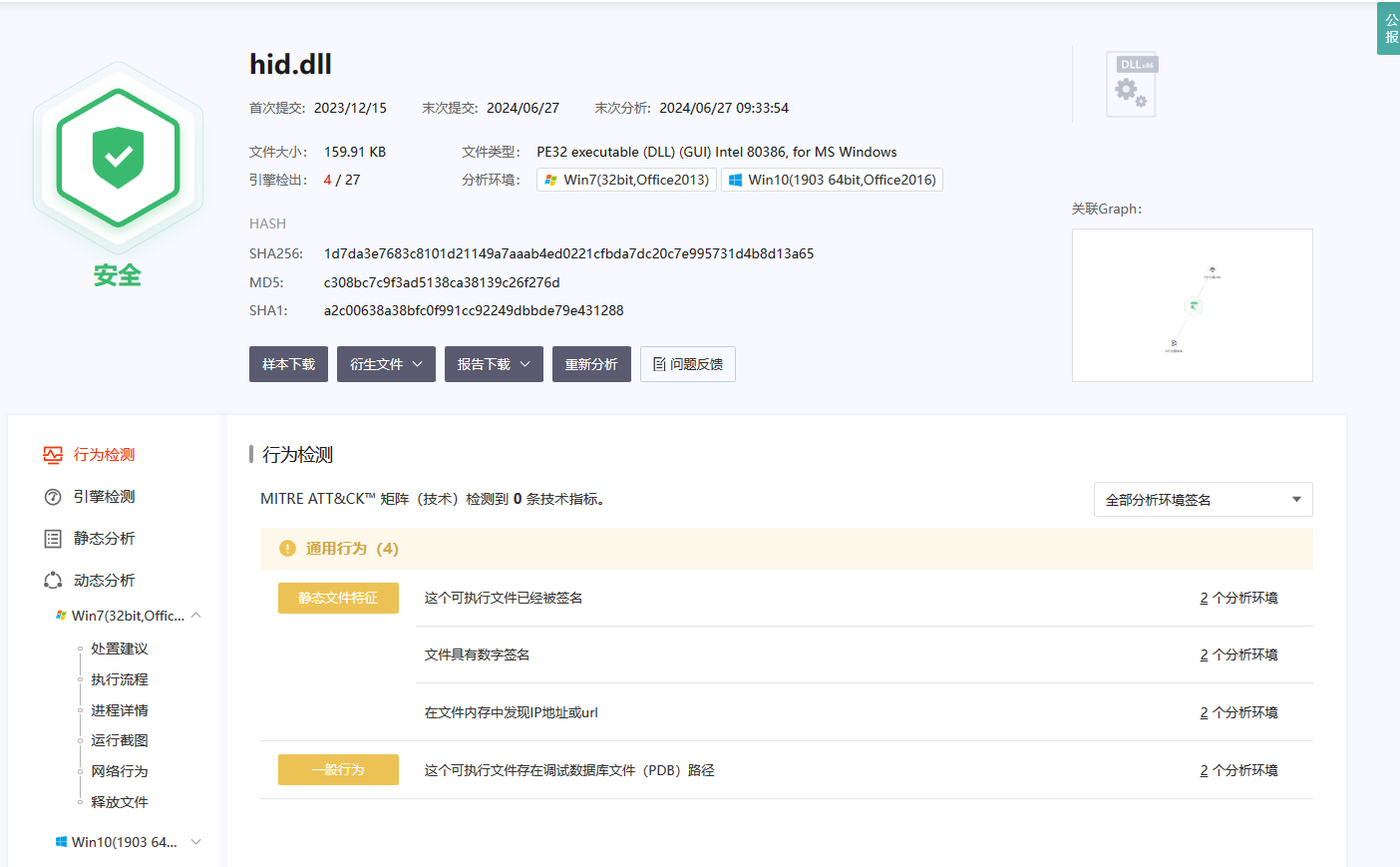
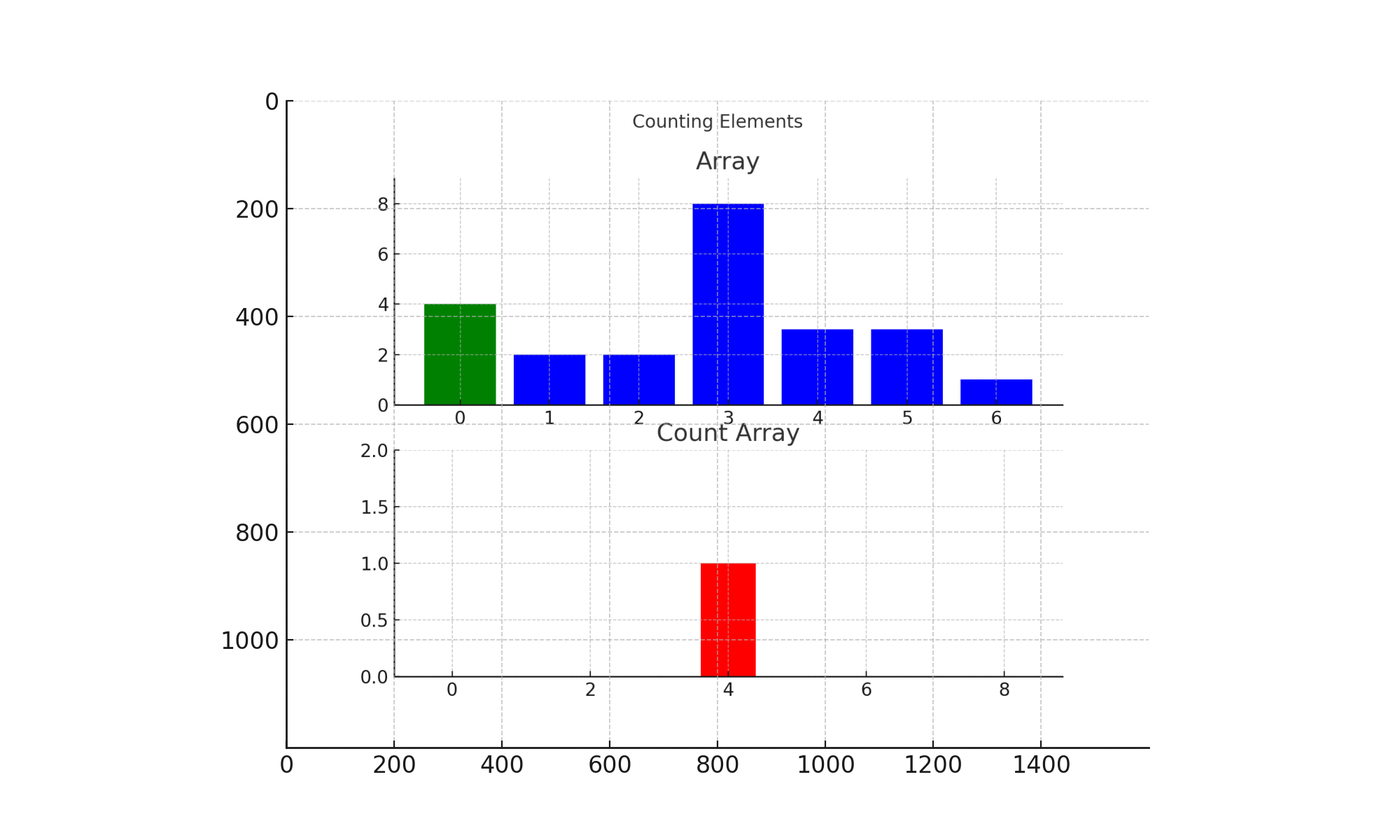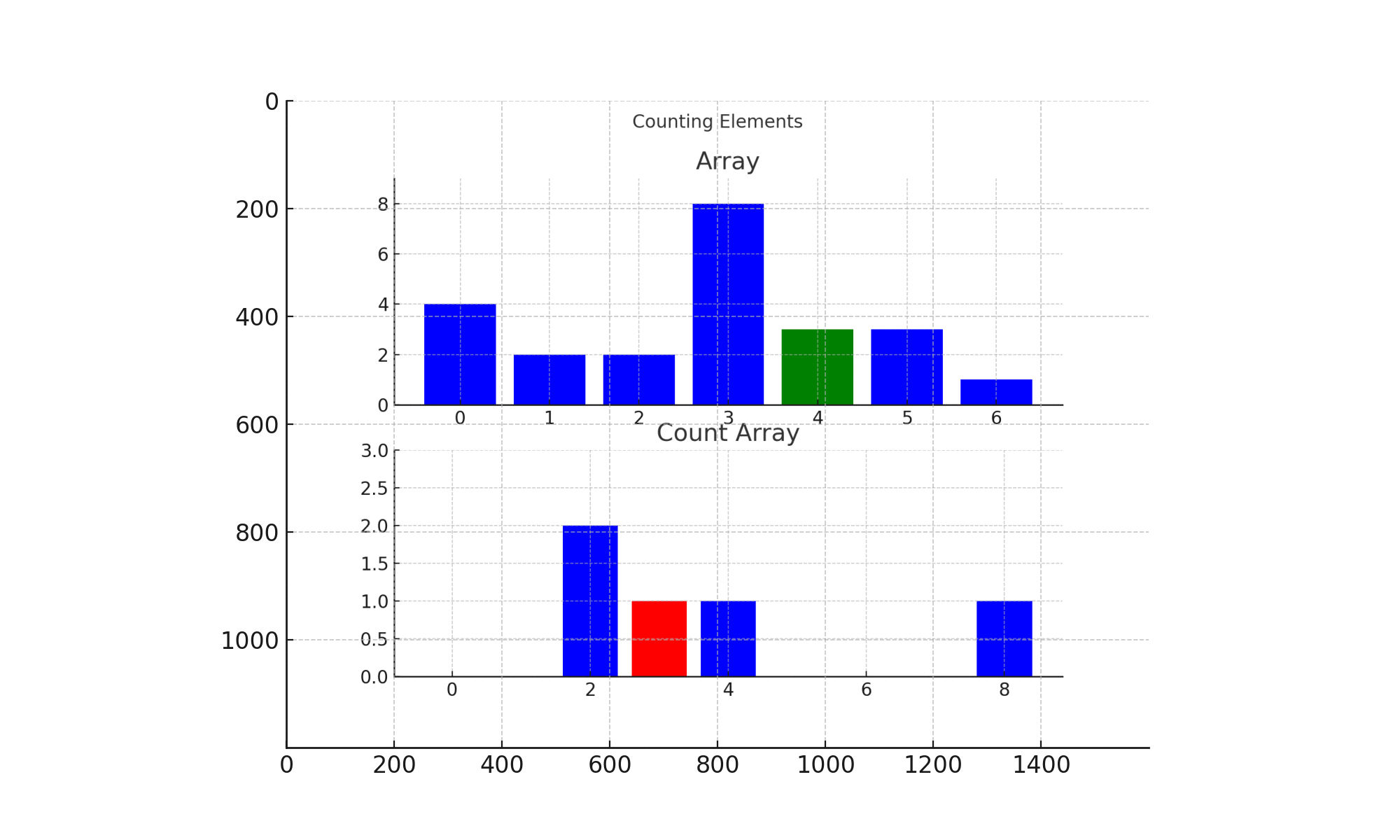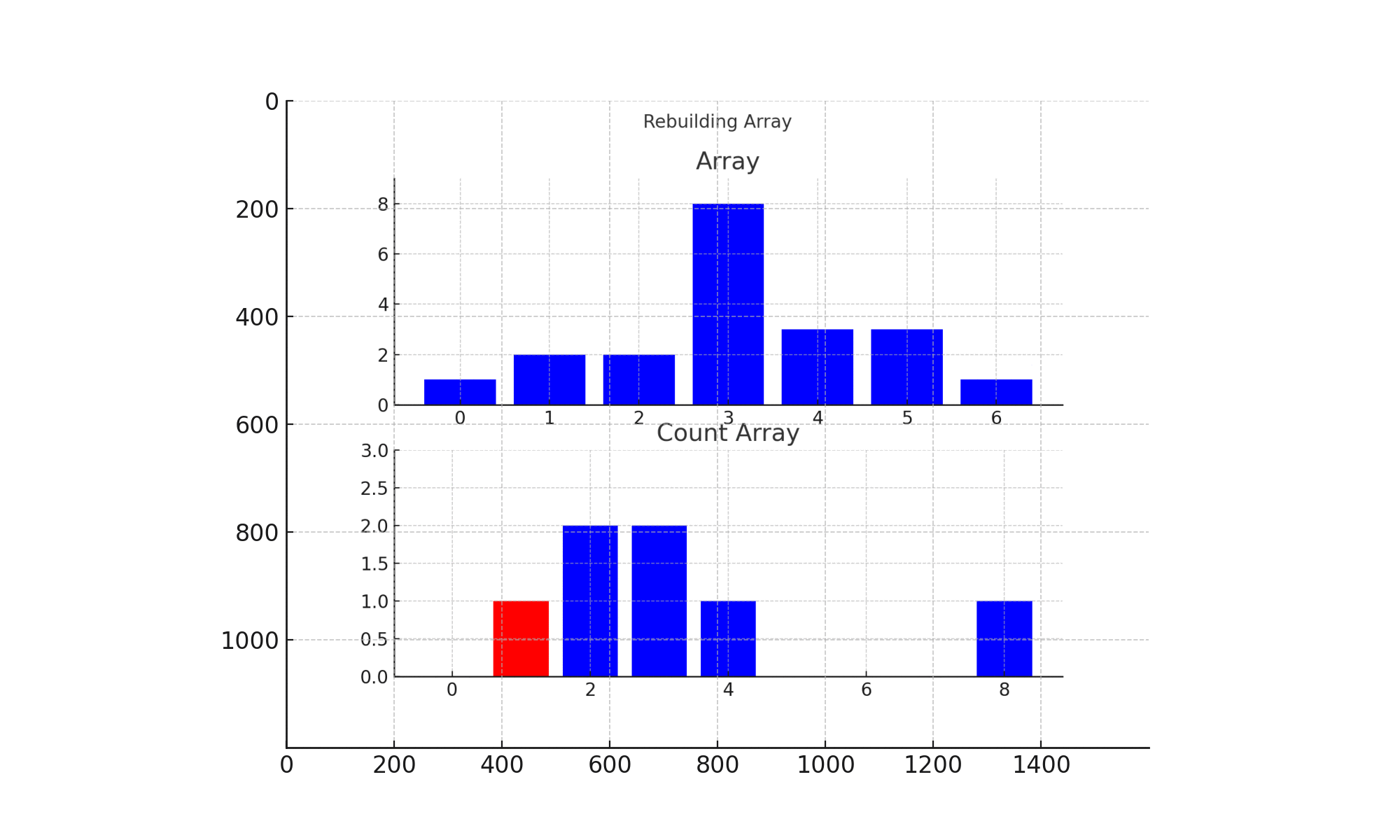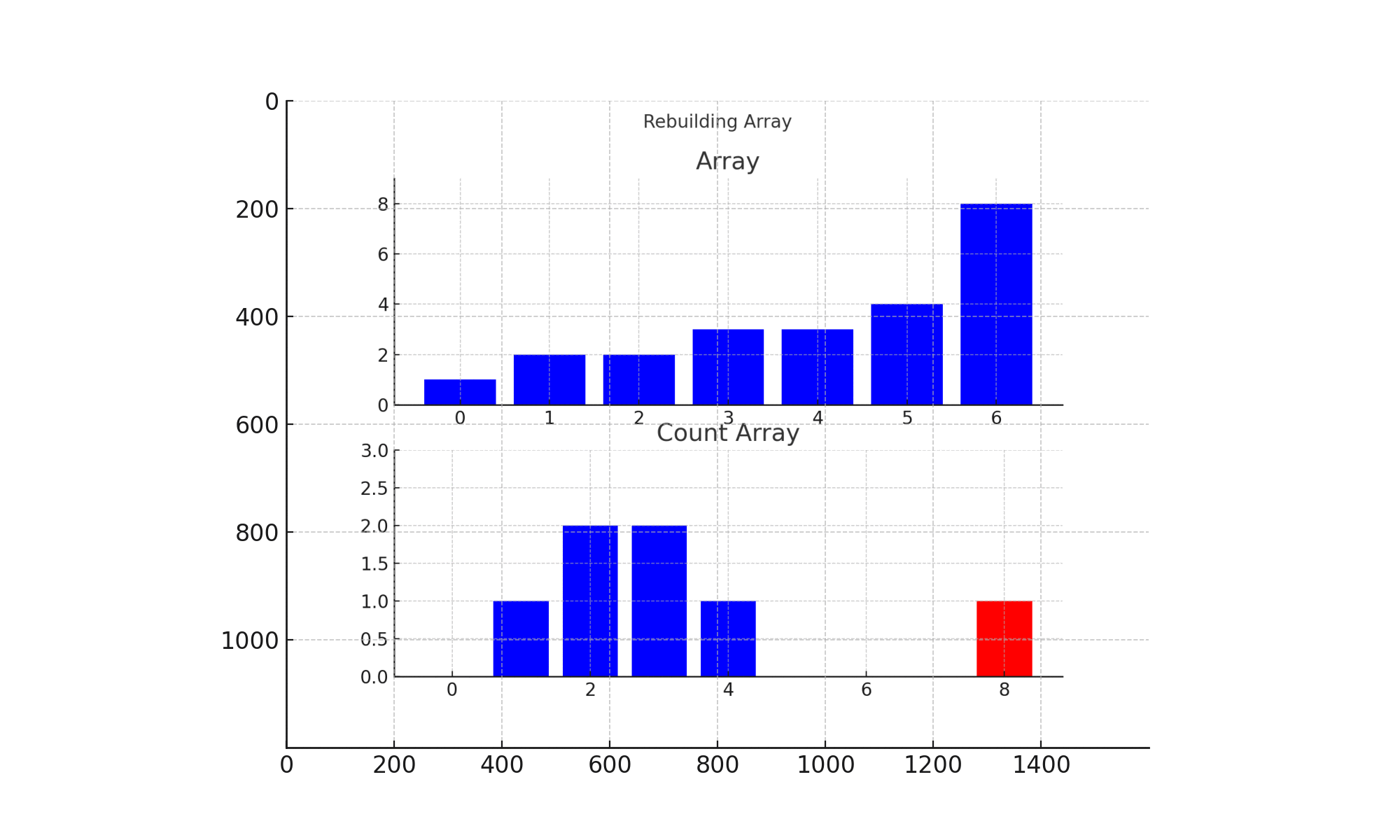
如表1所述,configure 脚本用于配置编译环境。执行该脚本时,会提示选择编译器。在培训环境中,我们使用 GNU Fortran 编译器,因此选择选项 2(GNU / gfortran)。
1 2
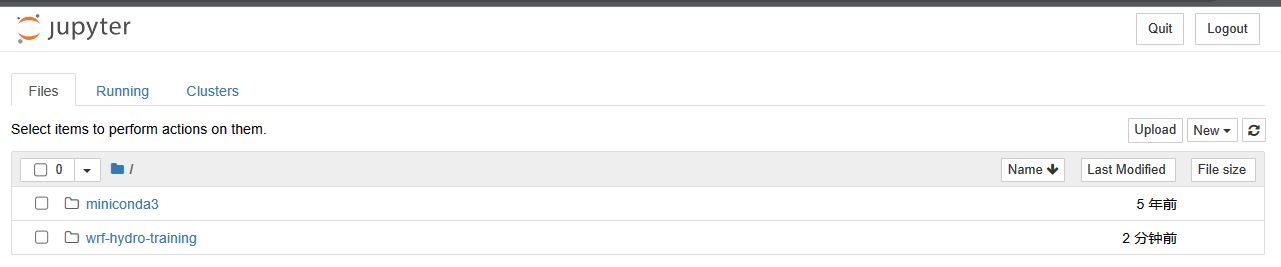
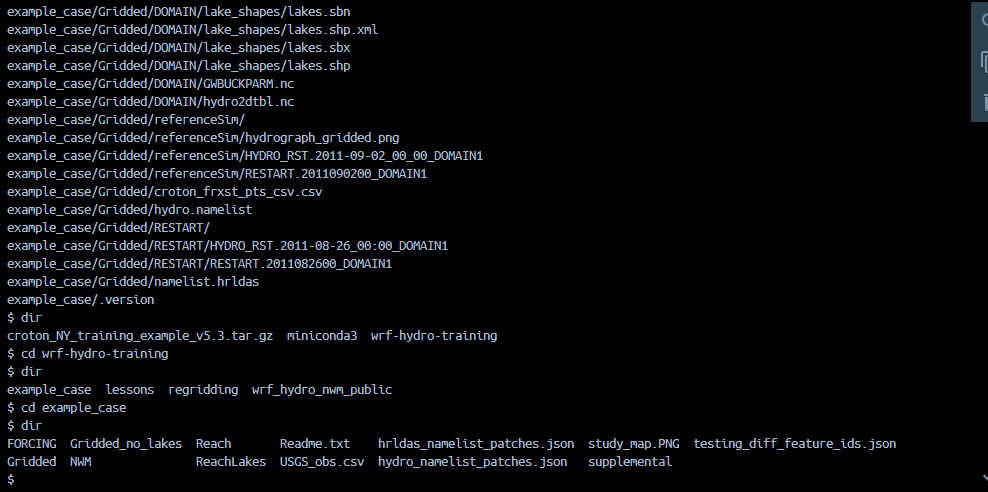
cd ~/wrf-hydro-training/wrf_hydro_nwm_public/trunk/NDHMS/ ./configure 2
./compile_offline_NoahMP.sh setEnvar.sh | tee compile.log
Step 6. 检查编译日志以确保编译成功
查看编译日志的最后几行,确保显示 “Make was successful” 和编译时使用的环境变量。
1
tail -13 compile.log
输出结果应包括:
1 2 3 4 5 6 7 8 9 10 11 12
***************************************************************** Make was successful
***************************************************************** The environment variables used in the compile: HYDRO_D=1 NCEP_WCOSS=0 NETCDF=/usr/local SPATIAL_SOIL=1 WRF_HYDRO=1 WRF_HYDRO_NUDGING=0 WRF_HYDRO_RAPID=0
Lesson 2 - 运行 WRF-Hydro
在这个课程中,我们将学习如何使用准备好的域来构建和运行 WRF-Hydro 模拟。
构建模拟
Step 1. 创建模拟目录
我们将为模拟创建一个目录:
1 2
mkdir -p ~/wrf-hydro-training/output/lesson2/run_gridded_default cd ~/wrf-hydro-training/output/lesson2/run_gridded_default
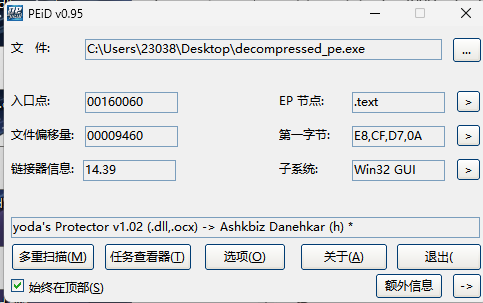
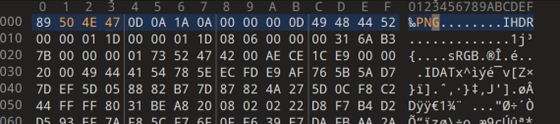
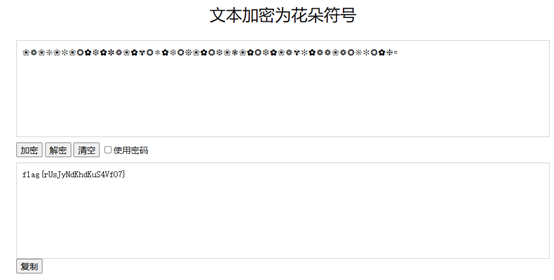
if success: print("Decompression and file writing successful.") else: print("Failed to decompress and write the file.")defdecompress_zlib_file(file_path, output_path):
d = 4885628697024674802233453512637565599092248491488767824821990279922756927662223348312748794983451796542248787267207054348962258716585568185354414099671493917947012747791554070655258925730967322717771647407982984792632771150018212620323323635510053326184087327891569331050475507897640403090397521797022070233 N = 89714050971394259600440975863751229102748301873549839432714703551498380713981264101533375672970154214062583012365073892089644031804109941766201243163398926438698369735588338279544152140859123834763870759757751944228350552806429642516747541162527058800402619575257179607422628877017180197777983487523142664487 ciphertext = 67254133265602132458415338912590207677514059205474875492945840960242620760650527587490927820914970400738307536068560894182603885331513473363314148815933001614692570010664750071300871546575845539616570277302220914885734071483970427419582877989670767595897758329863040523037547687185382294469780732905652150451
from Crypto.Util.number import long_to_bytes, bytes_to_long from Crypto.Util.strxor import strxor
m = pow(ciphertext, d, N) m = long_to_bytes(m) l = len(m) key = b'Life is like an ocean only strong-minded can reach the other shore' key = key[:l] m = strxor(m, key)